





Related Posts

Climate Summit Leaders Meet
Global Leaders Meet for Climate Change Summit Leaders from around the world have gathered for a crucial summit…
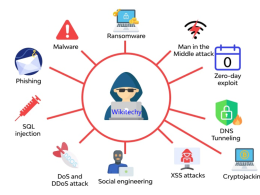
How Cybersecurity is Adapting to New Threats
Introduction: As a cybersecurity analyst with a passion for defending digital landscapes, I’ve seen firsthand how cybersecurity is…

Managing App Compatibility and App Store in Beta Software: Ensuring a Smooth Launch
Introduction: Beta software plays a critical role in the app development process, allowing developers to gather feedback, identify…
Decoding the EU AI Act Dilemma: Lessons from the OpenAI Saga
Decoding the EU AI Act Dilemma: Lessons from the OpenAI Saga Introduction Hi, I am Fred. I am…